Beyond Single Embeddings: Capturing Diverse Targets with Multi-Query Retrieval
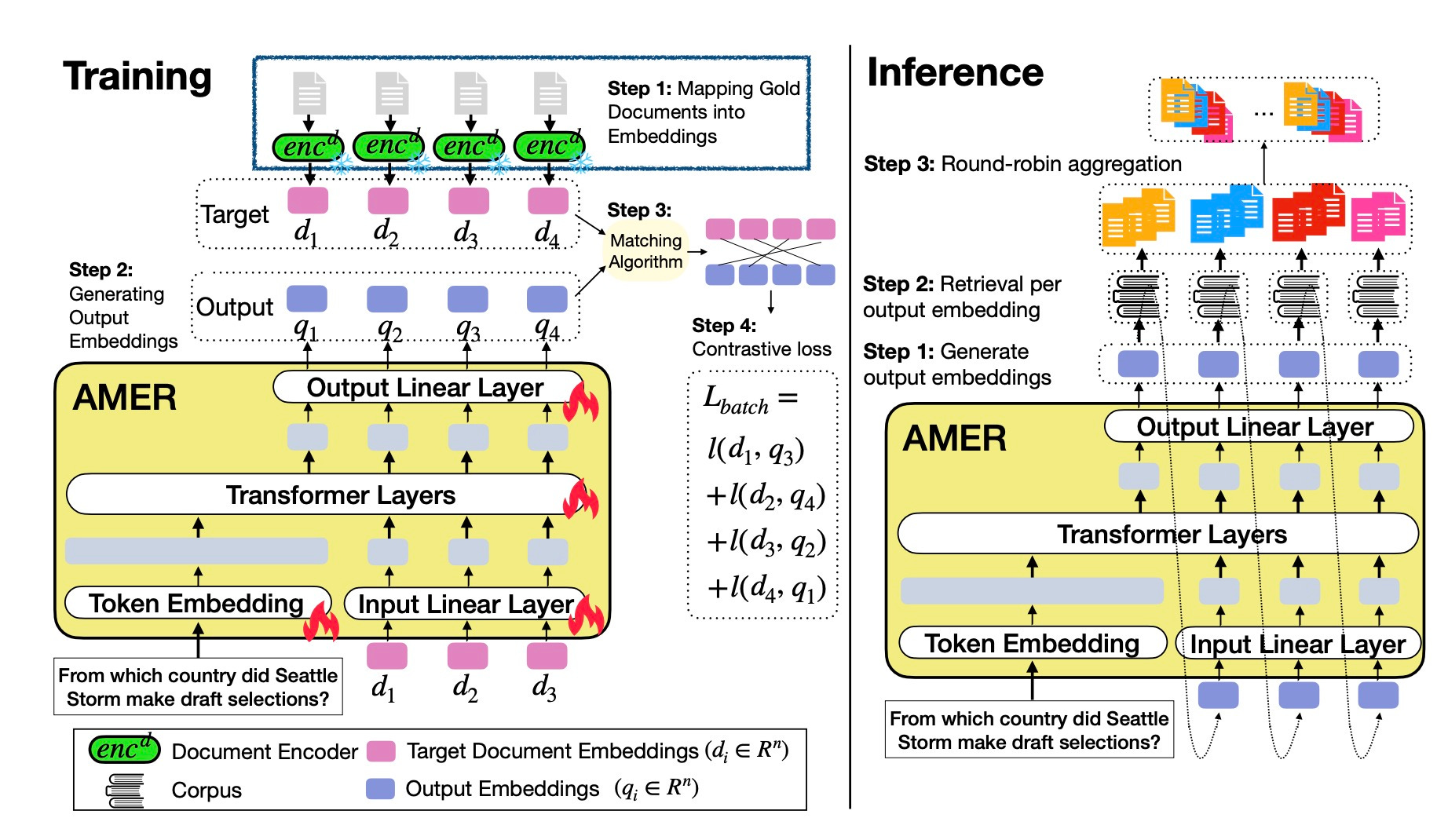
Single-vector retrieval breaks when queries have multiple distinct answers. The Autoregressive Multi-Embedding Retriever (AMER) generates a sequence of query embeddings instead of one, capturing diverse relevant documents for ambiguous or list-based queries. https://substackcdn.com/image/fetch/$s_!rHn4!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F2ec1de12-7834-43c6-9d2b-1cffdf8b7e14_1844x1070.jpegThe proposed model takes as input the target document embedding (order decided randomly) or predicted embedding in the previous step, and output the next embedding. During inference, AMER predicts the first embedding after seeing the query text, and outputs multiple query embeddings autoregressively.
FractalForensics: Proactive Deepfake Detection and Localization
This detector embeds fractal watermarks into images before they’re shared online. The watermarks survive normal edits but break under AI manipulation, showing you exactly where an image was altered. https://substackcdn.com/image/fetch/$s_!8eH5!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ff89b07b2-26e4-4239-a40d-ed120f9aeac9_2414x766.jpegWorkflow of the proposed FractalForensics.
Cambrian-S: Advancing Spatial Supersensing in Video
NYU and Stanford researchers built models that anticipate and organize complex visual experiences in long videos. The system selects relevant information and reasons about relationships between objects and events over time. https://substackcdn.com/image/fetch/$s_!6HNX!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F380cbe99-4d92-40a1-b0ab-352e7af92a8c_1790x1466.jpeg
The Underappreciated Power of Vision Models for Graph Structural Understanding
Vision models outperform graph neural networks at understanding global graph properties. GraphAbstract benchmark shows vision models intuitively grasp overall structure better than specialized GNNs.
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Models improve reasoning on both vision and text tasks by generating video sequences. The Video Thinking Benchmark shows that video generation helps models explore possibilities and think dynamically.
OlmoEarth-v1-Large
AllenAI released a foundation model for remote sensing trained on Sentinel and Landsat satellite data. OlmoEarth turns Earth data into insights within hours using ready-made infrastructure for both image and time series tasks.
BindWeave
ByteDance’s model for subject-consistent video generation uses cross-modal integration to keep subjects consistent across multiple shots. BindWeave already works in ComfyUI.
GEN-0
GeneralistAI built a 10B+ foundation model for robots with Harmonic Reasoning architecture. GEN-0 trains on 270,000+ hours of dexterous data to think and act simultaneously.
Step-Audio-EditX
StepFun open-sourced the first LLM-grade audio editing model. Control emotion, speaking style, breaths, laughs, and sighs through text prompts in a 3B-parameter model that runs on a single GPU. https://substackcdn.com/image/fetch/$s_!fZzc!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Faf776f14-08cd-47ea-8465-c002b6b64cd8_5012x932.pngAn overview of the architecture of Step-Audio-EditX
Rolling Forcing
This technique generates multi-minute streaming videos in real-time on a single GPU. Rolling Forcing denoises multiple frames jointly and anchors context with attention sinks for temporal consistency.
Retrieval Gets Smarter
Search broke when you started asking it to do two things at once. AMER fixes this by generating multiple query embeddings instead of forcing everything through a single vector. Here’s what that means. When you search for “climate change impacts and economic solutions,” a single-vector system picks one interpretation and misses the other. AMER showed 4x better performance than single embedding models on synthetic data where queries had multiple distinct answers arXiv [https://arxiv.org/html/2511.02770]. The gains get bigger when your target documents are conceptually distant from each other. The technique works by predicting query embeddings autoregressively. Each embedding captures a different facet of what you want. Think of it as asking the question from multiple angles simultaneously rather than hoping one angle catches everything. On real-world datasets, AMER showed 4-21% gains on average, but the improvements jumped to 5-144% on queries where target documents formed distinct clu
Replicate Mouse Tracker
Shoutout to fofr and kylancodes for putting together a dedicated Replicate model that generates HTML with a face that follows the cursor.
VideoSwarm 0.5
Shoutout to Cerzi for releasing VideoSwarm 0.5, a mass video player for easy browsing of large video datasets.