UniVA: Universal Video Agent
UniVA works like LEGO for video AI, you plug in whatever tools you need. The demo shows it tracking objects, editing footage, and understanding complex scenes all in one system.
Phys2Real: Sim-to-Real Transfer
This method trains robots in simulation then transfers that knowledge to the real world by accounting for real-world messiness. The robot learns what it doesn’t know and adapts accordingly.
Pelican-VL 1.0: The Embodied Intelligence Brain
Beijing’s Pelican-VL converts what robots see into 3D movement commands directly. Their DPPO training method works like human practice, make mistakes, reflect, improve.
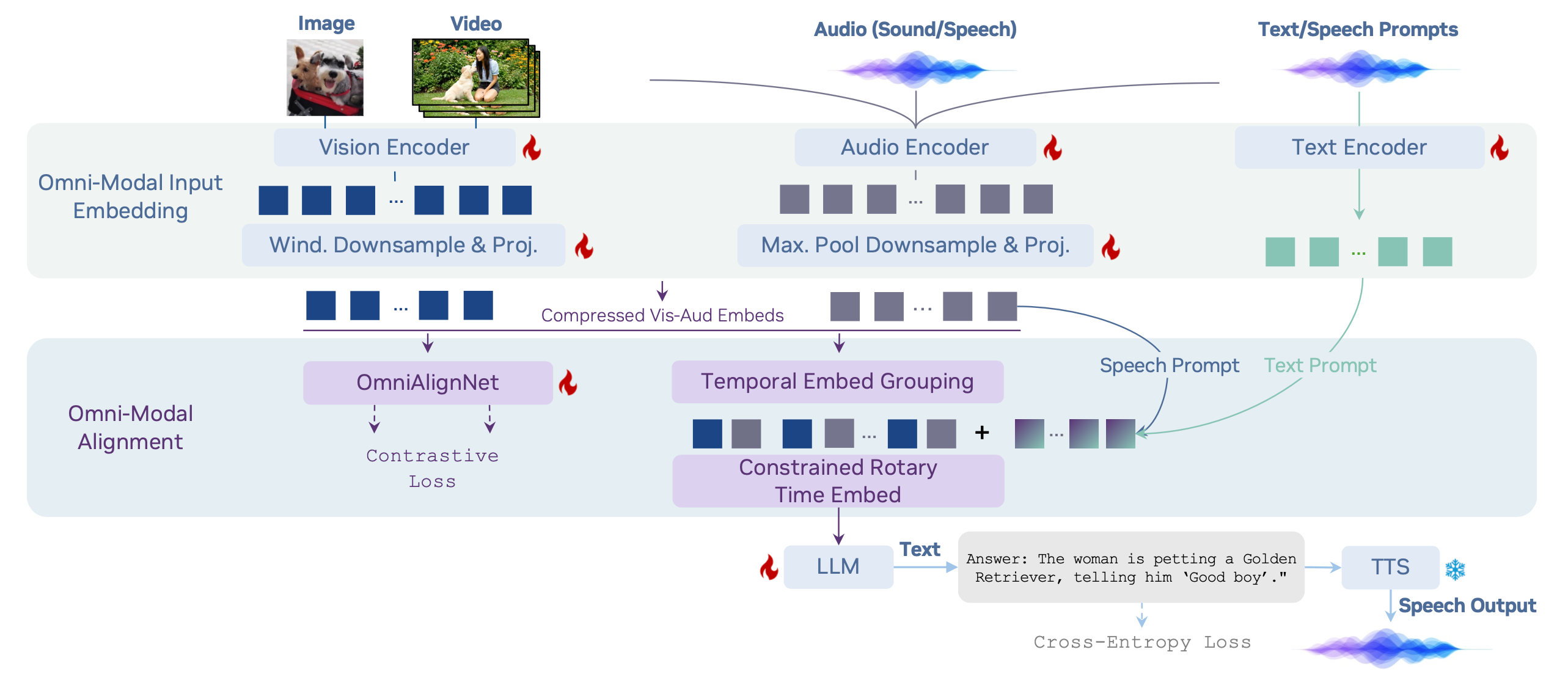
OmniVinci: Omni-Modal Understanding LLM
NVIDIA’s OmniVinci processes vision, audio, and language in one unified space. It beats Qwen2.5-Omni by 19% while using 6x less training data. https://substackcdn.com/image/fetch/$s_!gUPi!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fc6ff5d2a-81ba-41df-926d-6e11009c5cdb_2566x1108.png
Teaching AI to See the World More Like We Do
DeepMind used an “odd-one-out” test to show how differently AI sees things compared to humans. Their three-step alignment method fixes this, making AI group concepts the way you naturally would. https://substackcdn.com/image/fetch/$s_!w4ED!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F6e138237-cba0-4da9-90ff-16329311306c_1440x617.pngDiagram of their three-step model-alignment method.
SIMA 2
Google’s SIMA 2 plays games with you, learns through trial and error, and actually reasons about what to do. Talk to it through text, voice, or images, it understands high-level goals and figures out how to achieve them.
Depth Anything 3 (DA3)
DA3 generates depth maps from regular images with unprecedented accuracy. The demo shows it working on everything from selfies to satellite imagery.
Marble
World Labs’ Marble creates persistent 3D worlds from a single image, video, or text prompt. Upload a photo of your living room, get a walkable 3D space.
Holo2
H-Company’s Holo2 beats all computer-use benchmarks across web, desktop, and mobile. Drop it into your existing Holo setup, it works immediately on Ubuntu, Android, or Chrome. https://substackcdn.com/image/fetch/$s_!nTtj!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ff0c7ac30-6b34-4a8f-8018-467ea25caffa_4997x3836.pngWeb Surfing with Holo2
Music Flamingo
NVIDIA’s Music Flamingo understands full songs, not just clips. It analyzes music structure, identifies instruments, and reasons about compositions.
The Perception-to-Action Gap Closes
This week shows three distinct approaches to the same problem: how do you get AI to actually do things, not just understand them? Pelican-VL tackles this for robotics with its DPPO training method, the model practices tasks, fails, analyzes what went wrong, then adjusts. Think of it like teaching a robot to play piano: it doesn’t just memorize finger positions, it learns the relationship between what it sees and how to move. The Beijing team tested this on real humanoid robots doing manipulation tasks, and the results show genuine spatial reasoning emerging from visual input alone. SIMA 2 solves this in virtual environments. Google’s agent doesn’t just execute commands, it maintains persistent goals across gaming sessions, reasons about cause and effect, and learns new skills without being explicitly programmed. When you tell it “build a house,” it figures out it needs to gather materials first, find a good location, and plan the structure. This kind of multi-step reasoning with envi
dLLM
Zhanhui Zhou turned BERT into a chatbot using diffusion. Yes, you read that right—BERT can now chat.
Next Scene LoRA
OdinLovis built a LoRA that adds camera movement to image generation. Type “Next Scene” and watch your static image become a cinematic sequence.